規制インテリジェンスAPIの設計と実装:全社システム統合
はじめに
企業を取り巻く規制環境は日々変化しており、コンプライアンス対応は経営における重要な課題である。特に金融、医薬品、製造業などの規制産業では、規制要件の把握漏れや対応遅れが企業に深刻な影響を与える可能性がある。このような背景から、規制情報を効率的に収集・分析・配信する「規制インテリジェンス(Regulatory Intelligence)」の重要性が高まっている。
本コラムでは、企業全体のシステムに規制インテリジェンス機能を統合するためのAPI設計と実装について、技術的な詳細から実践的な導入手順まで包括的に解説する。
規制インテリジェンスの基本概念
規制インテリジェンスとは
規制インテリジェンスとは、企業が事業を行う上で遵守すべき法規制や業界ガイドラインを体系的に監視・分析し、関係部門に適切な情報を提供する仕組みである。従来は人手による規制情報の収集と分析が主流であったが、近年はAI技術を活用した自動化が進んでいる。
システム統合の必要性
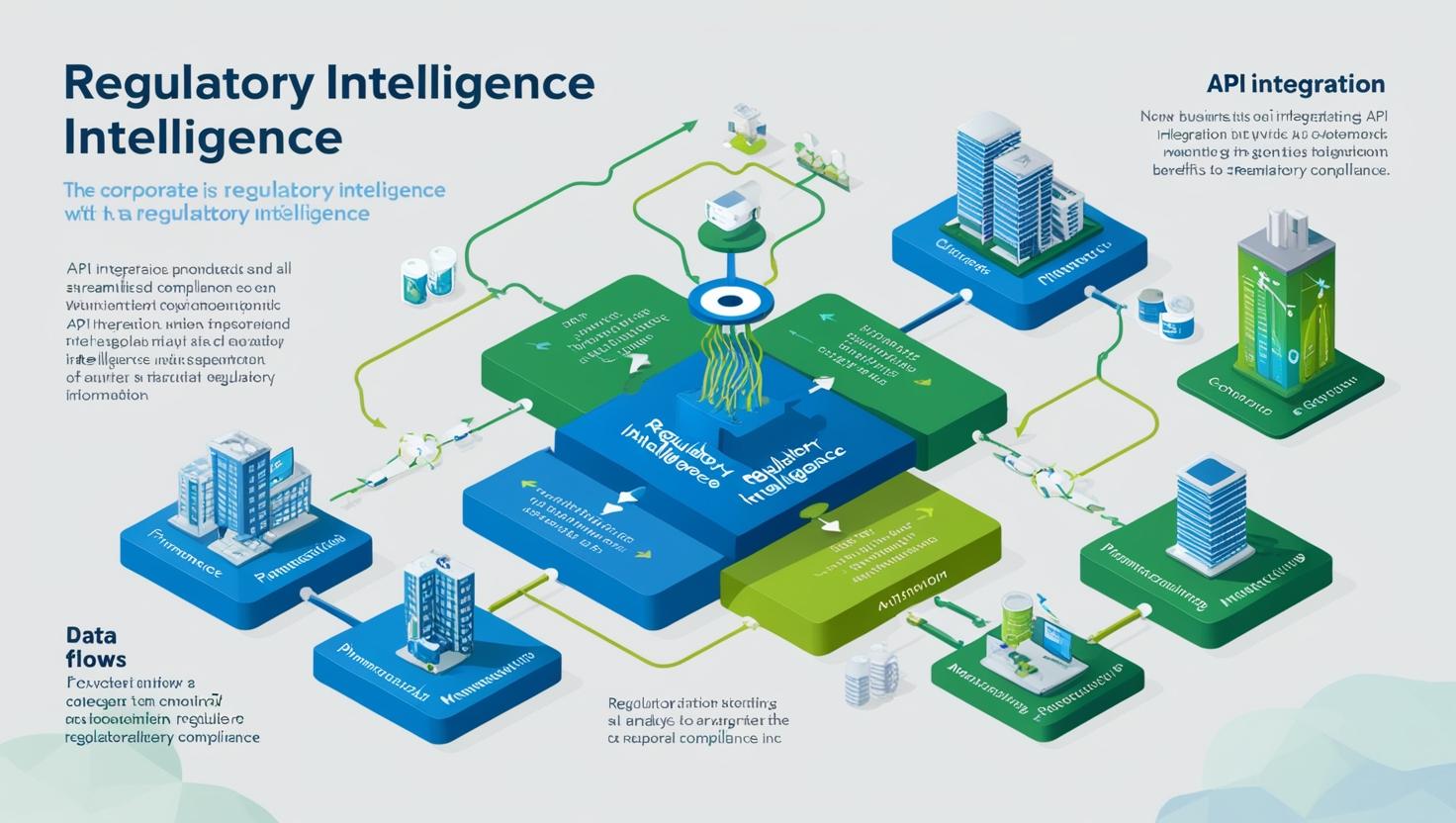
現代の企業では、ERP(Enterprise Resource Planning)、CRM(Customer Relationship Management)、リスク管理システムなど、多様なシステムが稼働している。規制インテリジェンスが真に有効に機能するためには、これらのシステムと連携し、業務プロセスに組み込まれる必要がある。APIによるシステム統合は、この要求を実現する最も効率的な手法である。
API設計の基本方針
RESTfulアーキテクチャの採用
規制インテリジェンスAPIは、RESTful(Representational State Transfer)アーキテクチャに基づいて設計する。RESTfulアーキテクチャの利点は以下の通りである:
- シンプルな設計: HTTPメソッド(GET、POST、PUT、DELETE)を活用した直感的なAPI
- スケーラビリティ: ステートレスな通信により高いスケーラビリティを実現
- 互換性: 標準的なWeb技術により幅広いシステムとの統合が可能
マイクロサービス指向の設計
規制インテリジェンスAPIは、以下の機能単位でマイクロサービスとして設計する:
- 規制情報収集サービス: 外部ソースからの規制情報取得
- 分析・解析サービス: 自然言語処理による規制内容の分析
- 通知・配信サービス: 関係部門への適切な情報配信
- 履歴管理サービス: 規制変更履歴とコンプライアンス対応記録の管理
API仕様の詳細設計
エンドポイント設計
規制インテリジェンスAPIの主要エンドポイントは以下の通りである:
# 規制情報の取得
GET /api/v1/regulations
GET /api/v1/regulations/{regulation_id}
# 規制変更通知の管理
POST /api/v1/notifications
GET /api/v1/notifications/{notification_id}
# コンプライアンス状況の確認
GET /api/v1/compliance/status
POST /api/v1/compliance/assessments
# 規制情報の検索
GET /api/v1/search/regulations?query={keyword}
データモデルの設計
規制情報を効果的に管理するため、以下のデータモデルを定義する:
Regulation(規制情報)
- regulation_id: 規制の一意識別子
- title: 規制のタイトル
- category: 規制カテゴリ(金融、環境、労働など)
- jurisdiction: 適用管轄(国、地域)
- effective_date: 施行日
- content: 規制内容
- impact_level: 影響度(高・中・低)
Notification(通知情報)
- notification_id: 通知の一意識別子
- regulation_id: 関連する規制のID
- target_departments: 対象部門リスト
- notification_type: 通知種別(新規、変更、廃止)
- urgency_level: 緊急度
- created_at: 作成日時
認証・認可機能
企業システムとの統合において、セキュリティは重要な要素である。OAuth 2.0プロトコルを基盤とした認証・認可機能を実装する:
- API Key認証: システム間通信における基本認証
- JWT(JSON Web Token): ユーザー認証とセッション管理
- RBAC(Role-Based Access Control): 役割ベースのアクセス制御
システム統合アーキテクチャ
企業システムランドスケープ
規制インテリジェンスAPIは、企業の既存システムと以下のように連携する:
ERPシステム連携
- 新規規制に基づく業務プロセスの自動更新
- コンプライアンス対応コストの予算計画への反映
リスク管理システム連携
- 規制リスクの自動評価と登録
- リスクマトリックスの動的更新
文書管理システム連携
- 規制関連文書の自動分類と保管
- コンプライアンス証跡の管理
データフロー設計
規制インテリジェンスシステムにおけるデータフローは以下の段階で構成される:
- 情報収集段階: 政府機関、業界団体からの規制情報収集
- 前処理段階: テキストのクリーニングと正規化
- 分析段階: 自然言語処理による内容分析と影響度評価
- 配信段階: 関係部門への適切な情報配信
- フィードバック段階: 対応状況の収集と分析
AI技術の活用
自然言語処理(NLP)の実装
規制文書の自動分析において、以下のNLP技術を活用する:
テキスト分類
- 規制カテゴリの自動分類
- 影響度レベルの自動判定
- 対象部門の自動識別
固有表現抽出(NER: Named Entity Recognition)
- 法令名、施行日、適用範囲の自動抽出
- 企業固有の用語・概念の識別
感情分析・重要度分析
- 規制変更の企業への影響度評価
- 緊急度の自動判定
機械学習モデルの構築
規制インテリジェンスの精度向上を目的として、以下の機械学習モデルを構築する:
教師あり学習モデル
- 過去の規制変更データを教師データとした影響度予測モデル
- コンプライアンス対応パターンの学習モデル
教師なし学習モデル
- 類似規制のクラスタリング
- 異常な規制変更パターンの検出
実装技術スタック
バックエンド技術
プログラミング言語: Python(Django REST Framework)またはJava(Spring Boot) データベース: PostgreSQL(構造化データ)+ Elasticsearch(全文検索) メッセージキュー: Apache Kafka(非同期処理) キャッシュ: Redis(高速データアクセス)
AI・ML技術
自然言語処理: spaCy、NLTK、Transformers(BERT、GPT) 機械学習: scikit-learn、TensorFlow、PyTorch データ処理: pandas、NumPy、Apache Spark
インフラストラクチャ
コンテナ化: Docker、Kubernetes クラウドプラットフォーム: AWS、Azure、GCP 監視・ログ: Prometheus、Grafana、ELK Stack
導入プロセスと段階的展開
フェーズ1: 基盤構築
最初の段階では、規制インテリジェンスAPIの基本機能を構築する:
- REST APIの基本エンドポイント実装
- データベーススキーマの設計と構築
- 認証・認可機能の実装
- 基本的な管理画面の構築
フェーズ2: AI機能統合
第二段階では、AI技術を活用した高度な分析機能を追加する:
- 自然言語処理エンジンの統合
- 機械学習モデルの訓練と実装
- 自動分類・影響度評価機能の実装
フェーズ3: システム統合
最終段階では、企業の既存システムとの統合を実現する:
- ERPシステムとの連携
- リスク管理システムとの統合
- ワークフロー自動化の実装
運用・保守の考慮事項
パフォーマンス監視
規制インテリジェンスAPIの安定運用のため、以下の監視項目を設定する:
- レスポンス時間: API呼び出しの応答時間監視
- スループット: 単位時間あたりの処理件数
- エラー率: API呼び出しの失敗率
- リソース使用率: CPU、メモリ、ディスク使用率
データ品質管理
AI分析の精度維持のため、継続的なデータ品質管理が必要である:
- データソースの信頼性評価: 情報源の定期的な検証
- 分析結果の精度検証: 人間の専門家による定期的なレビュー
- フィードバックループの構築: ユーザーからの修正情報の反映
セキュリティ対策
企業の機密情報を扱うため、以下のセキュリティ対策を実装する:
- データ暗号化: 保存時・転送時の暗号化
- アクセスログ監査: 全てのAPI呼び出しの記録と分析
- 脆弱性スキャン: 定期的なセキュリティ診断の実施
ROI(投資収益率)の評価
定量的効果の測定
規制インテリジェンスAPI導入の効果を以下の指標で測定する:
- 作業時間削減: 規制情報収集・分析作業の自動化による時間短縮
- コンプライアンス違反減少: 規制対応漏れの防止による罰金・制裁の回避
- 意思決定速度向上: 迅速な規制情報提供による経営判断の迅速化
定性的効果の評価
数値では測定困難な効果についても評価を行う:
- リスク管理能力の向上: 規制リスクの早期発見と対応
- 従業員満足度の向上: 単純作業の自動化による創造的業務への集中
- 企業レピュテーションの向上: 適切なコンプライアンス対応による信頼性向上
今後の発展方向
次世代AI技術の活用
規制インテリジェンスの更なる高度化を目指し、以下の技術導入を検討する:
大規模言語モデル(LLM)の活用
- GPT-4等の最新モデルによる高精度な規制文書解析
- 多言語対応による国際規制への対応強化
強化学習の導入
- ユーザーフィードバックを活用した継続的な性能改善
- 最適な通知タイミングとコンテンツの学習
グローバル展開への対応
多国籍企業における規制インテリジェンスのニーズに対応するため:
- 多言語・多地域対応: 各国の規制要件に対応した分析機能
- 時差対応: グローバルな運用に対応した24時間体制の監視
- 文化的差異の考慮: 地域特性に応じたコンプライアンス要件の対応
業界特化ソリューション
特定業界のニーズに特化したAPIの開発:
- 金融業界特化版: バーゼル規制、MiFID II等への特化対応
- 医薬品業界特化版: FDA、EMA規制への専門対応
- 製造業特化版: 環境規制、労働安全規制への対応
まとめ
規制インテリジェンスAPIの設計と実装は、現代企業のコンプライアンス対応を革新する重要な取り組みである。REST APIによる標準化されたインターフェース、AI技術を活用した高度な分析機能、そして既存システムとのシームレスな統合により、企業全体の規制対応能力を大幅に向上させることが可能である。
成功の鍵は、段階的な導入アプローチ、継続的な品質改善、そして組織全体でのコンプライアンス文化の醸成である。技術的な実装だけでなく、人材育成や業務プロセスの見直しも含めた総合的なアプローチが求められる。
今後、規制環境の複雑化と変化の加速化が予想される中、規制インテリジェンスAPIは企業の競争力維持と持続可能な成長を支える重要なインフラストラクチャとして、その重要性はますます高まるものと考えられる。






この記事へのコメントはありません。